In addition to the many different definitions for risk, there are lots of different ways to calculate risk. Having a way to assess a risk and ascribe a value is the core of any risk assessment: this valuation allows us to prioritize our risks and differentiate between those of low priority vs the higher, more urgent issues we need to deal with.
So we need a way to do these kinds of calculation but if we aren’t careful, we can end up with a model that’s too complicated for most people’s needs.
For example here’s a method that’s used in one industry in the US. If you write it down as a formula, you get something like this:
Risk = L2 * C where L2 = L1 * V and L1 = A * T
Or…
Risk = (((A*T)*V)*C)
But the calculation isn’t actually the product of the factors, it’s a mix. Some values are the result of adding the components and others are based on where these land on a 5×5 grid. So we can’t just multiply the values as the formula suggests
Basically, it’s a mess and it’s confusing, despite the most sincere and well-meaning efforts of the people who designed this. Remember, simple can be hard.
I know that I’ve been guilty of this myself. For example, I like a three factor model for risk:
risk = threat * vulnerability * impact.
I think that this definition is a great way to break down a risk and this approach also helps when it’s time to design mitigation measures. I used this as the core methodology for DCDR and for my assessments. It works and it’s relatively simple.
But relatively simple isn’t the same as really simple and that’s where we need to start sometimes. (This is meant to be KISS risk management after all…!) Even this approach can get confusing and it might be more than some people need, especially when they’re starting out.
Introducing, the World’s Simplest Risk Model™ (TWSRM)
So I wanted to find something even more simple. Here’s what I came up with. (You will also see why I didn’t pursue a career in calligraphy.)
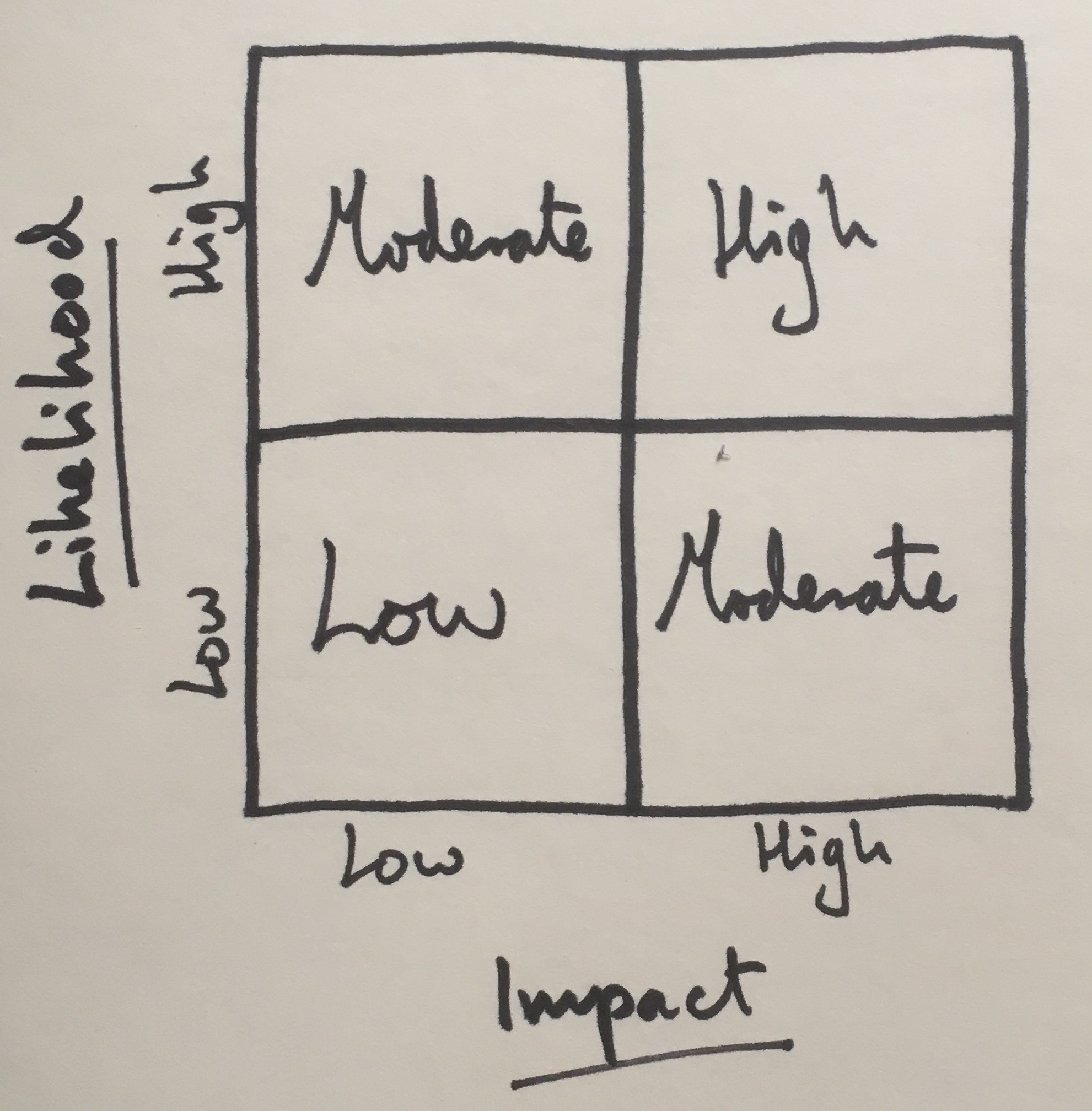
Here, we’re using a very simple definition for risk as being made up of two components: likelihood and impact.
Risk = likelihood x impact
We just rate each component ‘low’ or ‘high’ to get an overall risk rating of ‘low’, ‘moderate’ or ‘high’.
Next, we can jazz it up a little with some color to make the results easier to understand.
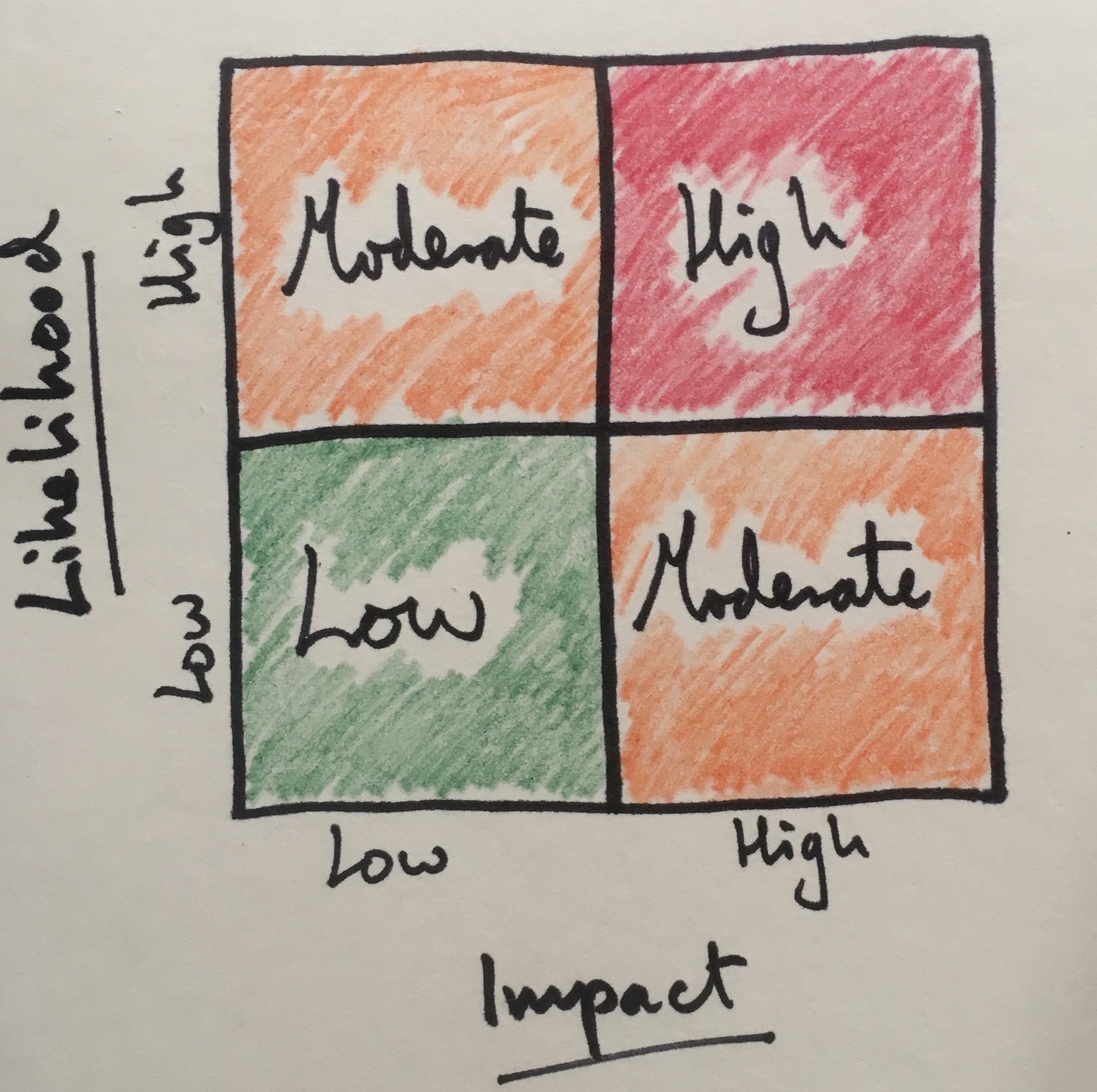
So we now have a process for assessing a risk, rating it and differentiating between risks of different severity.
Then, we add some simple numeric values. Now we also have a way to combine a number of risks to give us aggregate values or to compare individual risks by value.
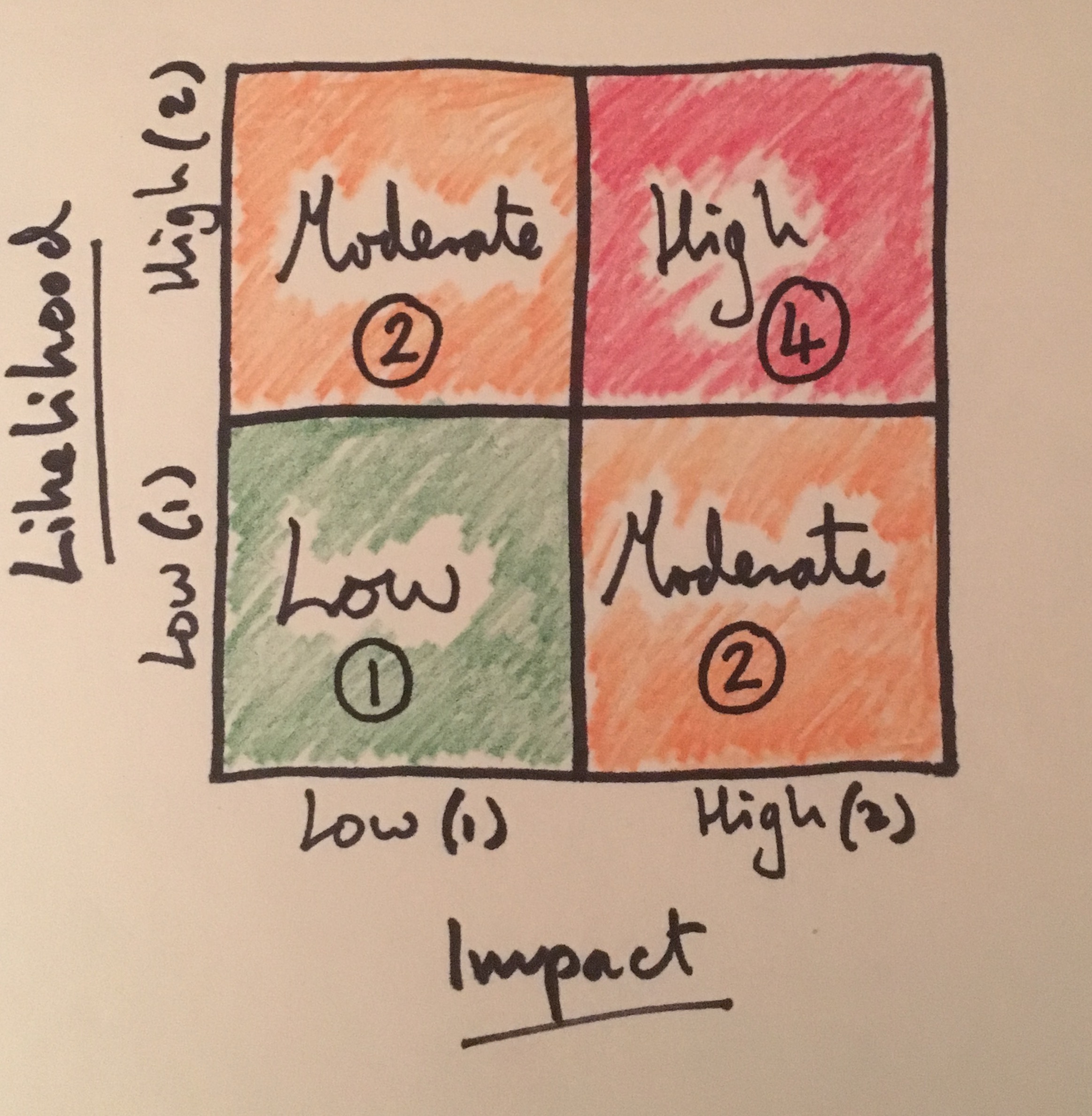
So we can assess a series of individual risks, compare these or combine the results to get an overall total.
Simple? Definitely. Too simple…?
KISS or too KISS?
No matter your level of expertise and experience, you’re probably thinking the same thing:
“That’s ridiculous. It’s far too simple.”
And in many ways you would be right.
This model is very simple (I did promise you the world’s simplest model after all). It won’t be practical in a lot of situations.
But it does work.
And what’s more, the vast majority of risk models don’t look significantly different from this. There may be more boxes on the grid or even additional factors but the process is basically the same.
So unless you have a very specific, technical use case (hi NASA), you don’t want a really complex model because these are difficult to follow and easy to get wrong.
(Remember Risk = L2 * C where L2 = L1 * V and L1 = A * T?)
And you also start to tie yourself in knots when you try to make something too mathematical and statistical when the underlying data isn’t really quantitative.
So even if The World’s Simplest Risk Model™ isn’t practical in most cases, what you need might not need to be much more complicated. KISS and build the most simple model you need to get the job done.
(BTW, The World’s Simplest Risk Model™ isn’t really trademarked so feel free to use this and the other material in the blog. Just be good enough to link back or acknowledge the source!)