Note that things are moving very quickly with AI and OpenAI. CatGTP in particular so some of the issues below may have been fixed by the time you read this. (Sadly, not the bits that involve humans.)
Some things to think about before you dive into GTP3
Like most of us, I love new toys. And like many others, I’ve been playing with OpenAIs tools since access opened up last year. With GTP4 scheduled for release soon and rumors that Google and Facebook both have pending AI releases, a lot will happen with AI in the near future.
However, there’s also a danger here. Not in the AI-is-going-to-kill-us kind of way (although that is a concern which is why I am always polite and say ‘good morning’ to HAL). Instead, the danger is that the current models look better than they are: credible, beautifully written answers are returned that are, in fact, beautifully written garbage, but only a subject-matter-expert would know. Or the data seems complete, but there are substantial blind spots.
So while everyone is playing with Chat GTP and announcing that they’ve had the AI write their [press release | exercise scenario | security assessment | book report], there are some flaws to watch out for.
Here’s what I keep in mind to help me get more out of the tool.
1 – The data isn’t current.
GTP3 does not draw live information from the internet, so the data available isn’t always current. For example, trying to get the price of Brent Crude returned the price from April 2021. A few moments later, the answer returned was from November 2020.
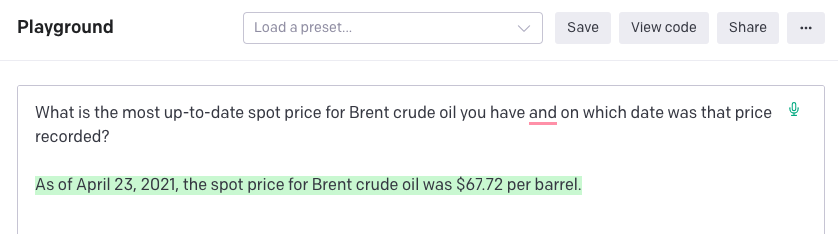
Moments later…

Having run this query several times before, the date of the value wasn’t always included in the answer, so you could easily get a plausible answer to a question but not realize that the result was out of date.
So think about how current the data needs to be to get you the answer you need. If it’s less than 12-18 months, the current model won’t get you what you need.
2 – Think about your prompts.
You’ll see that in the examples above, I added a second part to the question, requesting the date of the results. That’s a straightforward example of how the answer you get very much depends on the framing of the question. Even something as apparently obvious as getting a book summary might need careful thought. I asked the model to get me a summary of one of my books, sending it the title and author’s name. It returned a great summary, except it was someone else’s book. When I tinkered with the prompt, I got a review of my book. But again, if I hadn’t been familiar with the contents of the book I asked to be summarized, I would have had no idea that the results were from a different book.
You’ll see how specific prompts are becoming for image generation if you look at some of the prompts used in DALL-E and Stable Diffusion.

Prompt and image from Metaverse Post
So think about your question and be as specific as possible. GIGO applies to prompts as well as data.
3 – The models can only learn from the available data.
We need to keep in mind that although the corpus* these models are trained on is extensive, there’s a lot that’s not available. The discussions that led up to a decision might not be captured in the meeting minutes; the propriety data that went into a forecast is separate from the public record; records in languages other than English are a much smaller proportion of the training data.
So before you ask ChatGTP to produce a piece of analysis, you need to ask yourself the likelihood of it having access to what it needs to do a good job. And again, remember that a lot of the data will be months out of date.
(*It’s mandatory to include the word ‘corpus” when writing about AI models – I don’t make the rules.)
4 – They can’t do math.
So yes, if you ask what 5 * 4 is, you’ll get an answer, but you quickly run into problems if you try to feed the models a bunch of data and ask them to run calculations. I spent an entire afternoon trying to rebuild the DCDR assessment tool with OpenAI but got stuck on the base calculations immediately. I wrote the same prompt over and over again, rewriting the prompt and reformatting the data. I eventually ended up with something that would probably have run in Python (so the opposite of natural language prompts): still, the answers were wrong.
[Then I found this post](http://post https://help.openai.com/en/articles/6681258-doing-math-in-the-playground) (so at least it wasn’t just this user’s error…)

This will improve over time but, for now, if you need to crunch some numbers, use Python or everyone’s first true love, Excel.
5 – The models can be biased.
This is a complex and thorny issue, but there seem to be three significant issues concerning bias in the models.
First, the models are trained on material written by humans, and a proportion of people are terrible. Moreover, being horrible excites the social media algorithms (thanks, Mark!). So if the model sees 1000 posts, of which 10% are shared and commented on much more than the remainder, the model may think these are the ‘best’ posts. But it could be something awful that’s generating a lot of heat. So while these models are improving, there is still an underlying problem that a proportion of people aren’t.
Second, humans decide which data to feed into the models in the first place, so their biases (in this case, probably their preferences) influence what data the model sees. (As an aside, it will be fascinating to see how an AI from China addresses a problem compared to one from the US as the initial training data sets chosen by the research teams will likely be very different.)
Third, societal biases are reflected in data which ends up in your models. In the case of the US, an AI model might reject mortgage applications submitted by minorities because, historically, that’s what banks did. A lot of work is underway to determine how to scrub bias from models, but the underlying problem seems to be human, not mathematical (again).
Like several other issues mentioned here, this is something to remember when asking an AI for help. Careful prompt writing will be a big help, but you must also pay attention to the answer you get and sense-check it for bias. Unless you’re absolutely sure of how the model will perform, I wouldn’t leave an AI to publish text automatically at the moment. (Remember Tay.ai?)
 Welcome onboard
Welcome onboard
Despite all of this, I’m excited about how we can use these tools to enhance what we do already. The opportunities that widely available AI tools offer are incredible and create endless possibilities. However, as always, nothing’s perfect, so we need to proceed with care, and I hope that some of these ideas help you use these tools effectively and avoid some potential pitfalls.